Redes Neuronales: Aplicación de Descenso por Gradiente
Hoy en día segurmante nos hemos encontrado con la expresión “deep learning” o «aprendizaje profundo». Se refiere a un conjunto de herramientas que se han hecho muy populares en una amplia gama de campos de aplicación, desde el reconocimiento de imágenes, el reconocimiento del habla y el procesamiento del lenguaje natural hasta la publicidad dirigida y el descubrimiento de fármacos. El campo ha crecido hasta el punto de que existen sofisticados paquetes de software de dominio público, muchos de ellos producidos por empresas tecnológicas de alto nivel. Los fabricantes de chips también están adaptando sus unidades de procesamiento gráfico (GPU) a los núcleos centrales del aprendizaje profundo.
Antes de comenzar, para mas profundidad pueden consultar, por ejemplo, Cailin (2020) y Higham and Higham (2019). También pueden consultar estas notas de la materia “Fundamentos matemáticos del aprendizaje profundo” armadas por Julian Fernandez Bonder. Estas notas son un resumen de partes del libro “O. Cailin, Deep learning architectures - a mathematical approach, Springer Series in the Data Sciences, 2020”.
Precuela: Regresión lineal y logistica
Las redes neuronales no son un concepto reciente. Aparecieron por primera vez bajo el nombre de regresión lineal a principios del s. XIX. También podemos considerar la clasificación como como parte del concepto de redes neuronales.
Supongamos que tenemos un conjunto de datos \(X\), un conjunto de etiquetas \(Y\) y una función \(predict(w,x)\) donde \(w\) son parametros a encontrar de tal forma que
\[ predict(w,x) \approx y \]
La diferencia entre regresión y clasificación es simple:
- La regresión predice una variable continua \(y\).
- La clasificación predice una variable \(y\) Con un número finito de estados.
Suponiendo que tenemos \(n\) datos \(x\) el objetivo será
\[ \min_{w} \frac{1}{n}\sum loss(y_i,predict(w,x_i)) \]
Regresión lineal
La regresión lineal utiliza la función de predicción lineal
\(\text{predict}(w; x) = w^\top x\)
y la función de pérdida de error cuadrático
\((y, \hat{y}) = (y - \hat{y})^2\).
Cuando tenemos un conjunto de datos con \(n\) puntos (muestras) \(x_i\) y etiquetas \(y_i\), la regresión lineal puede escribirse como el siguiente problema de optimización:
\[ \min_w \; \frac{1}{n} \sum_{i=1}^{n} (w^\top x_i - y_i)^2. \]
La función objetivo es mínima si las predicciones \(w^\top x_i\) coinciden con las etiquetas \(y_i\) para todas las muestras \(i = 1, \ldots, n\).
Algunos algoritmos utilizan la suma en lugar del promedio en la función objetivo. Estos enfoques son equivalentes. En ese caso, es más simple trabajar en notación matricial, donde formamos una matriz \(X\) cuyas filas son las muestras \(x_i\). No es difícil ver que el problema anterior es equivalente a
\[ \min_w \; \|Xw - y\|^2, \]
donde la norma es la \(\ell_2\). Como este es un problema cuadrático convexo, es equivalente a sus condiciones de optimalidad.
Igualando la derivada a cero se obtiene
\[ 2 X^\top (Xw - y) = 0. \]
A partir de aquí, se obtiene la solución en forma cerrada de la regresión lineal
\[ w = (X^\top X)^{-1} X^\top y. \]
Regresión Logística
Aquí las etiquetas son variables discretas. La mayoría de los modelos de regresión emplean la función sigmoide
\[ \sigma(z) = \frac{1}{1 + e^{-z}} = \frac{e^z}{1 + e^z}, \]
ya que sus valores están en el intervalo \([0,1]\) y pueden interpretarse como probabilidades.
El nombre “regresión logística” puede resultar engañoso porque en realidad se trata de un problema de clasificación. En su forma más simple, se asumen etiquetas binarias \(y \in \{0,1\}\) y se predicen las clases positiva y negativa mediante probabilidades
\[ \mathbb{P}(y = 1 \mid x) = \sigma(w^\top x) = \frac{1}{1 + e^{-w^\top x}}, \]
\[ \mathbb{P}(y = 0 \mid x) = 1 - \sigma(w^\top x) = \frac{e^{-w^\top x}}{1 + e^{-w^\top x}}. \]
Denotando \(\hat{y} = \mathbb{P}(y = 1 \mid x)\) como la probabilidad de predecir 1, la función de pérdida es la entropía cruzada
\[ \text{loss}(y, \hat{y}) = -y \log \hat{y} - (1 - y)\log(1 - \hat{y}). \]
Pérdida de entropía cruzada:
Aunque la pérdida de entropía cruzada puede parecer complicada, en realidad es bastante simple. Cuando una muestra pertenece a la clase positiva, tenemos \(y = 1\), y la pérdida se reduce a \[
\text{loss}(1, \hat{y}) = -\log \hat{y}.
\] Dado que \(\hat{y}\) está en el intervalo \((0,1)\) debido a la función sigmoide, la entropía cruzada se minimiza cuando \(\hat{y} = 1\). Como se obtienen resultados similares para \(y = 0\), la entropía cruzada es mínima cuando las etiquetas \(y\) coinciden con las predicciones \(\hat{y}\).
Luego, no es difícil ver que el problema de regresión logística puede escribirse como
\[ \min_w \; \frac{1}{n} \sum_{i=1}^{n} \left( \log(1 + e^{-w^\top x_i}) + (1 - y_i)\, w^\top x_i \right). \]
Redes Neuronales
Red Neuronal
Para una entrada \(x\) con una etiqueta \(y\), queremos minimizar la pérdida entre la predicción \(predict(w;x)\) y la etiqueta \(y\). La función \(predict\) tiene dos parámetros: \(w\) son los “pesos” mientras que \(x\) el dato de entrada. Teniendo \(N\) muestras, el problema de minimización es el siguiente
\[ \operatorname{min}_w\frac1N\sum_{i=1}^N \operatorname{loss}(y_i, \operatorname{predict}(w;x_i)). \]
Capas (Layers)
La entrada \(x\) entra en las primeras capas, la salida de la primera capa va a la segunda capa y así sucesivamente. Matemáticamente hablando, una red con \(L\) capas tiene la estructura
\[ \hat y = \operatorname{predict}(w;x) = (f_L \circ \dots \circ f_1)(x), \]
donde \(f_1,...,f_L\) son capas individuales. La mayoría de estas capas dependen de los pesos \(W\). Por otro lado, sólo la primera capa \(f_1\) depende directamente de la entrada \(x\). Dado que dos capas que no están una al lado de la otra (como la primera y la tercera) no están conectadas directamente, esto permite la propagación sencilla de los valores de las funciones y sus derivadas.
Para fijar ideas, supongamos que la red tiene \(L\) capas, con las capas \(1\) y \(L\) siendo respectivamente las capas de entrada y salida. Supongamos que la capa \(l\) (para \(l = 1, 2, 3, \dots, L\)), contiene \(n_l\) neuronas. Así, \(n_1\) es la dimensión de los datos de entrada. En general, la red mapea desde \(\mathbb{R}^{n_1}\) a \(\mathbb{R}^{n_L}\). Usamos \(W^{[l]} \in \mathbb{R}^{n_l \times n_{l-1}}\) para denotar la matriz de pesos en la capa \(l\). Más precisamente, \(w_{jk}^{[l]}\) es el peso que la neurona \(j\) en la capa \(l\) aplica a la salida de la neurona \(k\) en la capa \(l-1\). Similarmente, \(b^{[l]} \in \mathbb{R}^{n_l}\) es el vector de sesgos para la capa \(l\), así que la neurona \(j\) en la capa \(l\) usa el sesgo \(b_j^{[l]}\).
En la Figura se ve un ejemplo con \(L = 5\) capas. Aquí, \(n_1 = 4\), \(n_2 = 3\), \(n_3 = 4\), \(n_4 = 5\), y \(n_5 = 2\), así que \(W^{[2]} \in \mathbb{R}^{3 \times 4}, \quad W^{[3]} \in \mathbb{R}^{4 \times 3}, \quad W^{[4]} \in \mathbb{R}^{5 \times 4}, \quad W^{[5]} \in \mathbb{R}^{2 \times 5}, \quad b^{[2]} \in \mathbb{R}^3, \quad b^{[3]} \in \mathbb{R}^4, \quad b^{[4]} \in \mathbb{R}^5, \quad b^{[5]} \in \mathbb{R}^2.\)
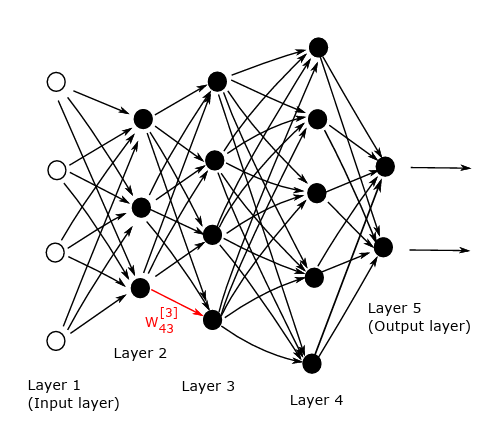
Dado un input \(x \in \mathbb{R}^{n_1}\), podemos resumir la acción de la red dejando que \(a_j^{[l]}\) denote la salida, o activación, de la neurona \(j\) en la capa \(l\). Así, tenemos:
\[ a^{[1]} = x \in \mathbb{R}^{n_1}, \] \[ a^{[l]} = \sigma\left(W^{[l]} a^{[l-1]} + b^{[l]}\right) \in \mathbb{R}^{n_l}, \quad \text{para } l = 2, 3, \dots, L. \]
Supongamos ahora que tenemos \(N\) conjunto de datos, o puntos de entrenamiento, en \(\mathbb{R}^{n_1}\), \(\{x^{\{i\}}\}_{i=1}^N\), para los cuales hay salidas objetivo dadas \(\{y(x^{\{i\}})\}_{i=1}^N\) en \(\mathbb{R}^{n_L}\). Luego la función de costo o pérdida que queremos minimizar tiene la forma:
\[ Cost = \frac{1}{N} \sum_{i=1}^N loss(y(x^{\{i\}}), a^{[L]}(x^{\{i\}})), \]
Funciones de activación
La función de activación suele escribirse como \(\sigma :\mathbb{R}\to\mathbb{R}\) y su operación sobre el vector \(W^{[l]} a^{[l-1]} + b^{[l]}\) se entiende en sentido componente. Ejemplos de funciones de activación son:
\[ \begin{aligned} &\text{Sigmoid:}&\sigma(z) &= \frac{1}{1+e^{-z}} ,\\ &\text{ReLU:}&\sigma(z) &= \operatorname{max}\{0,z\}, \\ &\text{Softplus:}&\sigma(z) &= \log(1+e^z), \\ &\text{Swish:}&\sigma(z) &= \frac{z}{1+e^{-z}} ,\\ \end{aligned} \]

Softmax layer
La función de pérdida de entropía cruzada requiere que su entrada sea una distribución de probabilidad. Para ello, la capa softmax se aplica directamente antes de la función de pérdida. Su formulación es la siguiente
\[ \operatorname{softmax}(a_1,\dots,a_K) = \frac{1}{\sum_{k=1}^K e^{a_k}}(e^{a_1}, \dots, e^{a_K}). \]
La exponencial garantiza que todas las salidas sean positivas. La normalización asegura que la suma de las salidas es uno. Por lo tanto, se trata de una distribución de probabilidad. Cuando una capa densa precede a la capa softmax, se utiliza sin ninguna función de activación (ya que, por ejemplo, ReLU haría que muchas probabilidades fueran iguales).
Funciones de pérdida
(Mean) squared error \[ \operatorname{loss}(y,\hat y) = (y-\hat y)^2. \]
Cross-entropy \[ \operatorname{loss}(y,\hat y) = - \sum_{k=1}^K y_k\log \hat y_k. \]
Binary cross-entropy \[ \operatorname{loss}(y,\hat y) = - y\log \hat y - (1-y)\log(1- \hat y). \]
El error cuadrático medio se suele utilizar para problemas de regresión, mientras que ambas entropías cruzadas para problemas de clasificación. El primero para problemas multiclase (\(K>2\)) y el segundo para problemas binarios (\(K=2\)).
Comencemos con el ejemplo
using LinearAlgebra, RDatasets, Random, Statistics, PlotsTrabajaremos con el conjunto de datos Iris contiene mediciones de 150 flores de iris de tres especies diferentes: setosa, versicolor, virginica. Cada muestra incluye la longitud y el ancho del sépalo, y la longitud y el ancho del pétalo, todas medidas en centímetros. Es ampliamente utilizado en aprendizaje automático para tareas de clasificación y demostraciones educativas.
iris = dataset("datasets", "iris")
X = Matrix(iris[:, 1:4])
y = iris.SpeciesX = Matrix(iris[:, 1:4])
y = iris.Speciesscatter(iris.PetalLength, iris.PetalWidth, group=iris.Species, xlabel="Petal Length", ylabel="Petal Width",
title="Iris Dataset", legend=:topleft)A nuestros datos los vamos a dividir en 2: - Entrenamiento: (\(X_{train}\), \(y_{train}\)) - Testeo: (\(X_{test}\), \(y_{test}\))
- Vamos a calcular \(w^* = argmin_w l(y_{train},\hat{y}(X_{train},w))\)
- Usaremos \(w^*\) para evaluar \(l(y_{test},\hat{y}(X_{test}, w^*))\) y así evaluar si el modelo funciona con datos con los que no fue entrenado.
function split(X, y; dims=1, ratio_train=0.8)
n = length(y)
n_train = round(Int, ratio_train*n) #Redondeamos el corte
i_rand = randperm(n) # Permutamos los indices
i_train = i_rand[1:n_train] # Usamos el 80% para train
i_test = i_rand[n_train+1:end] # El resto lo usamos para test
Xₜᵣₐᵢₙ = X[i_train,:]
yₜᵣₐᵢₙ = y[i_train]
Xₜₑₛₜ = X[i_test, :]
yₜₑₛₜ = y[i_test]
return Xₜᵣₐᵢₙ, yₜᵣₐᵢₙ, Xₜₑₛₜ, yₜₑₛₜ
endAntes de utilizar algun modelo de optimización, debemos normalizar nuestros datos. No normalizar los datos puede generar los siguientes problemas:
Convergencia lenta: Los algoritmos de optimización, como el descenso de gradiente, pueden tardar más en converger si las características tienen escalas muy diferentes.
Dominio de variables: Las variables con valores más grandes pueden dominar el proceso de aprendizaje, lo que significa que el modelo puede sesgarse hacia estas características y no tener en cuenta adecuadamente las características con valores más pequeños.
Problemas numéricos: Las diferencias extremas en la escala de las características pueden conducir a problemas numéricos, lo que puede afectar la precisión de los cálculos.
CUIDADO! - Los coeficientes de normalizacion deben ser calculados solo con los datos de entrenamiento. Si en el proceso de calcular los coeficientes se utilizan los datos de testeo se estarian filtrando informacion de los datos de testeo en el proceso de entrenamiento (Data Leakage)
- El conjunto de datos \(y\) en nuestro ejemplo es categorico, por lo tanto no hay que normalizarlo porque no representa un valor numerico.
function normalize(X_train, X_test; dims=1)
col_mean = mean(X_train; dims)
col_std = std(X_train; dims)
return (X_train .- col_mean) ./ col_std, (X_test .- col_mean) ./ col_std
endPor otro lado hay que realizar el one-hot encoding que convierte etiquetas categóricas en vectores binarios. Por ejemplo, en el conjunto de datos Iris, las especies “setosa”, “versicolor” y “virginica” se podrían representar como [1, 0, 0], [0, 1, 0] y [0, 0, 1], respectivamente.
function onehot(y, classes)
y_onehot = zeros(length(classes), length(y))
num_of_class = 1:length(classes)
for i in 1:length(y)
y_onehot[:,i] = y[i].==classes
end
return y_onehot
endY juntamos todo en una sola función:
function prepare_data(X, y; do_normal=true, do_onehot=true, kwargs...)
X_train, y_train, X_test, y_test = split(X, y)
if do_normal
X_train, X_test = normalize(X_train, X_test; kwargs...)
end
classes = unique(y)
if do_onehot
y_train = onehot(y_train, classes)
y_test = onehot(y_test, classes)
end
return X_train', y_train, X_test', y_test, classes
endPodemos construir una red neuronal simple, model, con las siguientes tres capas:
- La primera capa es una capa densa con la función de activación ReLU.
- La segunda capa es una capa densa con la función de activación identidad.
- La tercera capa es la softmax. Sus parámetros se almacenarán en la siguiente estructura.
mutable struct RedSimple{T<:Real}
W1::Matrix{T}
b1::Vector{T}
W2::Matrix{T}
b2::Vector{T}
endRandom.seed!(73)
W1 = randn(5, size(X_train,2))
b1 = randn(5)
W2 = randn(size(y_train,1), 5)
b2 = randn(size(y_train,1))
model = RedSimple(W1,b1,W2,b2)Gradiente
Un requisito previo para el “entrenamiento” de redes neuronales es el cálculo eficiente de las derivadas. Aunque parezca complicado, no es más que una simple aplicación de la regla de la cadena. Consiste en pasos hacia delante (forward pass) y pasos hacia atrás (backward pass). El paso hacia adelante comienza con la entrada, calcula los valores en cada neurona y termina evaluando la función de pérdida. El paso hacia atrás comienza con la función de pérdida, calcula las derivadas parciales hacia atrás y las encadena para obtener la derivada compuesta.
A este método se lo conoce como back propagation.
\[ L(w) := \sum_{i=1}^n \operatorname{loss}(y_i, f(w;x_i)). \]
\[ \nabla L(w) = \sum_{i=1}^n \operatorname{loss}'(y_i, f(w;x_i))\nabla_w f(w;x_i). \]
\[ \begin{aligned} z_l &= W_la_{l-1} + b_l, \\ a_l &= \sigma_l(z_l) \end{aligned} \]
\[ \begin{aligned} \nabla_{W_l} f &= \nabla_{W_l}a_L = \nabla_{z_L}a_L\nabla_{z_{L-1}}a_L\nabla_{a_{L-1}}z_{L-1}\dots \nabla_{z_l}a_l\nabla_{W_l}z_l, \\ \nabla_{b_l} f &= \nabla_{b_l}a_L = \nabla_{z_L}a_L\nabla_{z_{L-1}}a_L\nabla_{a_{L-1}}z_{L-1}\dots \nabla_{z_l}a_l\nabla_{b_l}z_l. \end{aligned} \]
\[ \begin{aligned} \nabla_{a_{l-1}} z_l &= W_l, \\ \nabla_{z_l} a_l &= \operatorname{diag}(\sigma_l'(z_l)). \end{aligned} \]